 – More Questions Than Answers")
High Frequencies (HF) – More Questions Than Answers
The picture on top shows 100 ms of the room response after an initial impulse was radiated by the loudspeaker.
Since low frequency (LF) energy is distributed over time what we see is mostly high frequency sound:
After arrival of the direct sound at about 5 ms, strong reflexions arrive within the first 20 ms. When the first reflexions have passed, the sound fills the room and comes back to the microphone after multiple reflexions. The energy dies down after a while because every reflection absorbs a bit of energy.
Similar to LF (see the Room Modes blog), the HF spectrum shows strong influence of interfering reflexions in typical listening rooms:
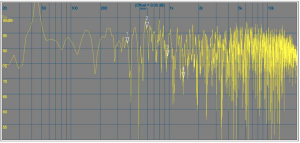
The difference between the HF and LF spectrum
LF modes produce intensive level variations with often wide frequency spread from one to the next mode. Because of the wide spread, single resonating frequencies stand out as boomy or one-note bass in our perception. Measures taken to smooth the LF response usually lead to clearly audible gains in clarity and definition.
Compared to LF, it is relatively easy to absorb HF energy. A porous absorber needs to be one quarter of wavelength deep to absorb the corresponding frequency, and all others above it. And objects of medium to small size are all it needs to diffuse the HF sound field (more about that in the Diffraction blog).
So why are dedicated listening rooms not created completely absorptive for HF’s?
The resulting HF frequency response would look impressive (with good loudspeakers)!
If we absorb all HF and nearly no LF energy, the room sound would be dull, with strong LF coloration.
Absorbing LF down to the lowest room modes will hardly leave space for us and the equipment.
So, the total absorption path is simply impossible to go for most rooms. Besides, have you ever been in a reflexion-free room? Most people will agree that this is a strange environment. Our eyes can see walls but our ears receive no reflexions. Since we are masters of pattern recognition this unnatural situation is quite unpleasant. It feels like a slight deafness.
Interestingly, the perception of those dense amplitude ripples in the HF spectrum due to reflexions is not as bad as they look in above graph. Our ears tend to smooth over them in a fashion similar to the graph below:
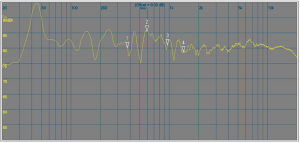
Same situation as above, but smoothed with 1/6 octave bandwidth.
Some more bits about perception
If we enter a room new to us, after a few minutes our listening mechanism adapts to room acoustics like our eyes adapt to different lighting conditions. The ear separates the direct sound from the room contribution.
Since the direct sound has the shortest path, it arrives before the reflected sound. If the time and amplitude difference is large enough, the reflection hardly „disturbes“ the direct sound.
How much reflections do reduce the quality of reproduction seems to differ between listeners. There are just as many recipes for perfect HF treatment as there are people talking about it. Even sound engineers prefer very different environments for different kinds of music and as a matter of habit for their work.
(U) We can just leave them untreated and listen to several rooms at reproduction time:
The room(s) where the recording(s) were made. Maybe one or even several that were added by artificial reverberation. And our listening room. This is the most natural listening environment for our ears, but maybe a little too reverberant to discern small details in the recording.
To reduce the listening room’s influence, sitting close to the speakers helps (called nearfield listening).
And using loudspeakers with narrow radiation patterns, like horn systems.
Some say loudspeakers with wide radiation create a „they are here“ feeling. Because they excite the listening room similar to real musicians in our room. In contrast, horns create a more „I am there“ feeling.
(A) We absorb equal amounts of energy from LF to HF
The question would be how much? And where? Often areas that produce strong first reflexions will be treated by acoustical damping panels. However, practical solutions often do not cover frequencies below 100 Hz well. Hence, a controlled, „dry“, sometimes over-clinical sound is experienced, with too much LF energy left. If you go this way, please start with LF treatment! If not overdone, good results can be achieved.
The disadvantage is you need more energy to create similar sound levels in such rooms. You need more expensive loudspeakers and amplifiers. Even so, for some the result sounds too dry and less dynamic.
(D) We use diffusion to redistribute reflected energy
Why? Compared to concert halls, listening rooms are small and do not create evenly distributed late reflexions from all sides. If we manage to turn specular reflexions into diffuse ones, they arrive from all sides at all times. Hereby they introduce such dense interference ripples onto our loudspeakers response, that no coloration is perceived. Still, this can be too much room contribution, and sounds too „diffuse“. Besides, diffusing low frequencies again needs large objects, leaving little room to enjoy the result. Finally, diffusors work best if listened to at some distance. Usually more than 1 m, which limits their application. And prevents their use at first reflection points in small rooms.
(C) Combinations
For about two decades I am now using „abfusors“ to treat overly reverberant listening spaces. Of course I did not invent the idea. Sound engineers tired of too dry control room acoustics started to place small reflective objects in front of large absorbers. With some mathematical optimization this leads to a good combination of control and diffusion. The result can be an open sounding space with just the right amount of control.
Final remark: If you enjoy the luxury of a dedicated listening room or look for some minimal treatment of other spaces, first try to find out which frequency range needs treatment. And besides the lowest frequencies, overdoing things might finally disturb our perception by a lack of consensus between visual and auditory cues.